I
would like to present a simple R code which can load tweets timelines of
specified users, then, in the loaded tweets, find frequent terms, some associations
with specified terms and display the results as terms clouds. I think such
visualization is more effective for sentiment analysis if compared with the
calculation of positive and negative words, and it can give more intuitive tips
for analytics. Users
can use the following functions: gettweets(), freqterms(), assoc("term"), stock("symbol").
The
gettweets() function allows users to load the latest tweets from a
specified list of twitter users, such as: CNN, WSJ, Reuters, Bloomberg, etc.
Please, use this function only once per analysis, because if you load tweets
too often, Twitter can block you IP. With
the following command, you can specify the maximum number of latest tweets that
can be loaded from each user's timeline:
gettweets(number), the default number is 100. The function freqterms() will output more
frequent terms.
The
function assoc("term") will display the terms that are correlated
with some specified term, e.g. assoc("apple").
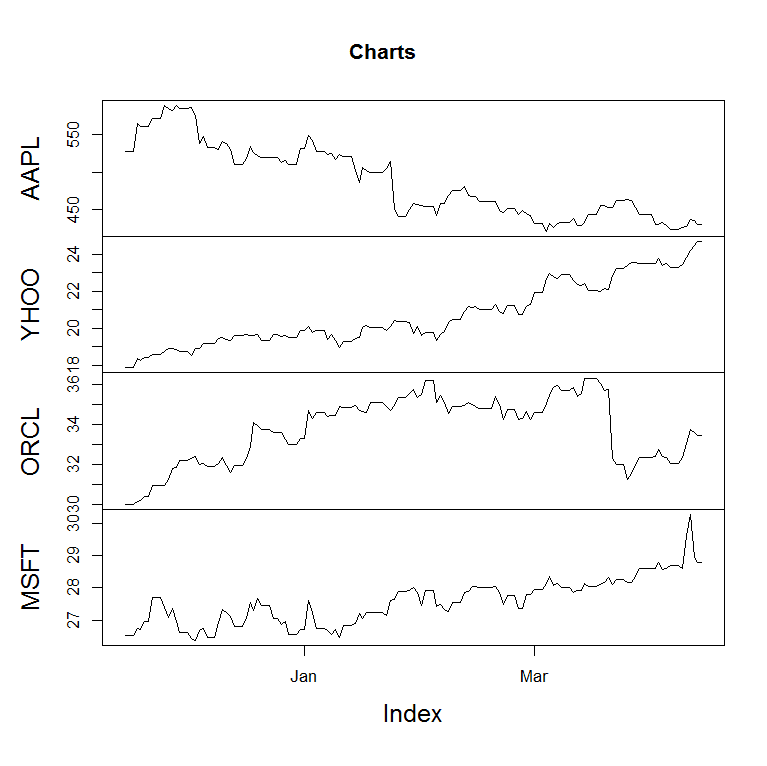
The
function stock("symbol") will display a stock chart for some
specified symbol, a cloud of terms which are correlated with the specified
symbols, and the forecasting, based on the ARIMA model. Each company has its
own specified symbol, e.g.: Google - GOOG, Apple - AAPL, Yahoo - YHOO, Dell -
DELL, Oracle - ORCL, Microsoft - MSFT, Cisco - CSCO, etc. For example, the function stock("GOOG")
will display a stock chart fro Google.
Download R-code
To
work with this program, you need to install R (more info at http://r-project.org). Before
starting the program, you need to install the additional packages, you can do
this using the following commands:
install.packages("twitteR")
install.packages("tm")
install.packages("RJSONIO")
install.packages ("forecast")
install.packages ("quantmod")
Our
next step is going to be the use of multivariate forecasting algorithms based
on the vector ARMA model. These algorithms can include many time series into analyses,
the time series describe both stock prices and quantitative characteristics of
tweets. I think such an approach will give the narrower and more precise
forecasting. To the effective tweets characteristics, we are planning to use
the theory of semantic fields, frequent sets, associative rules, Galois
lattice, the formal concepts analysis. Such an approach can be found in our
previous investigations at
http://arxiv.org/ftp/arxiv/papers/1302/1302.2131.pdf
http://bpavlyshenko.blogspot.com/2012/12/the-model-of-semantic-concepts-lattice.html
http://bpavlyshenko.blogspot.com/2012/12/investigation-of-concept-end-of-world.html
http://bpavlyshenko.blogspot.com/2013/01/data-mining-of-concept-end-of-world-in.html
Please write your comments.
Printscreens of functions performing:
gettweets():
freqterms():

assoc("apple"):

stock("GOOG"):