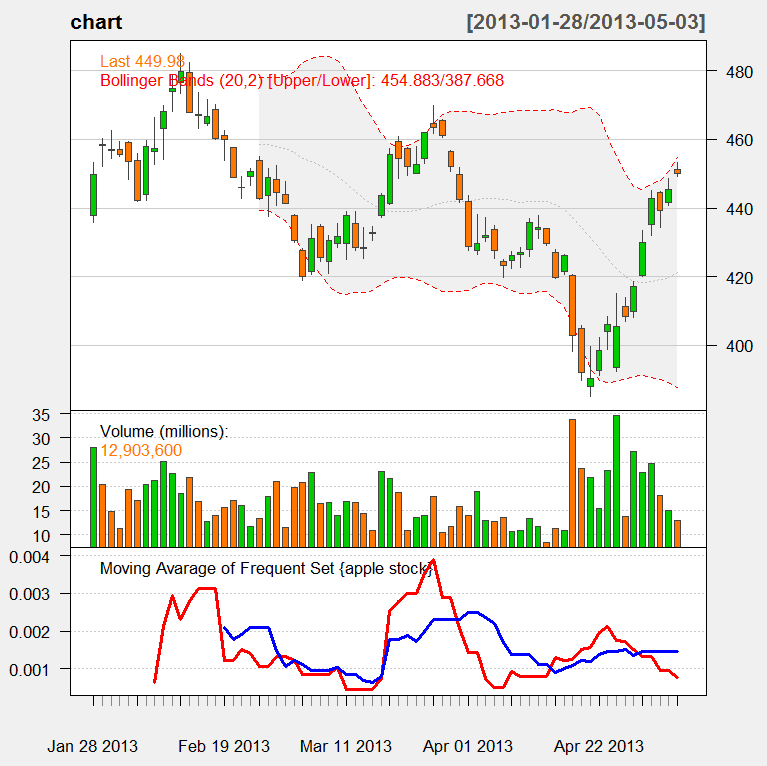
Previous part.
Yesterday the final of Eurovision Song Contest took place.
Before the final, I made a
forecasting on the basis of data mining of tweets.
The results of my analysis were the following:
winner is going to be a singer from Denmark, the next three places will go to Ukraine, Russia and Ireland.
The anounced results of the final are:
1st place - Denmark, 2nd place - Azerbaijan, 3rd place - Ukraine, 4th place - Norway, 5th place - Russia.
Our data mining analysis has correctly detected the winner and the top places for Ukraine and
Russia. However, Ireland was mistakenly included into top five, and Azerbaijan and Norway were not mentioned at all.
I have conductd analysis again and found a basic mistake in the algorithm. In the analysis, a great number of associative rules appears and they must be filtered out. For the filtration, I chose the words of high frequency, which included "Ireland" and ignored "Azerbaijan" and "Norway". That is why the tweets with those words were excluded from the analysis. The mistake is in the fact that high-frequency keywords may be used in some other contexts and have nothing to do with the analysis with the favourites of the competition. I have conducted the analysis once again, it was on the basis of the same tweets which were loaded in May 17. All countries participating in the contest were taken into account. And this forecasting turned out to be very close to the real results of Eurovision Song Contest.


Besides, it is worth saying that Twitter is not evenly widespread in all countries, that is why the number of tweets from different countries was also different. Additionally, there is also an unpleasant political factor. E.g., Ukraine is in the top 3 due to the results, but Russia (Ukraine's neighbour) gave it only one point.
The results presented are for the same source of tweets, obtained with the consideration of previous errors:
lhs rhs support confidence lift
1 {denmark,
norway} => {win} 0.014610390 0.9000000 1.3137441
2 {denmark,
favourites} => {win} 0.011363636 1.0000000 1.4597156
3 {azerbaijan,
norway} => {win} 0.011363636 0.8750000 1.2772512
4 {denmark,
ukraine} => {win} 0.008116883 0.8333333 1.2164297
5 {azerbaijan,
russia} => {win} 0.008116883 0.8333333 1.2164297
6 {azerbaijan,
denmark} => {win} 0.008116883 0.7142857 1.0426540
7 {finland,
sweden} => {win} 0.008116883 1.0000000 1.4597156
8 {russia,
ukraine} => {win} 0.006493506 0.8000000 1.1677725
9 {azerbaijan,
ukraine} => {win} 0.006493506 0.8000000 1.1677725
10 {norway,
ukraine} => {win} 0.006493506 0.8000000 1.1677725
11 {norway,
russia} => {win} 0.006493506 0.8000000 1.1677725
12 {denmark,
russia} => {win} 0.006493506 0.8000000 1.1677725
13 {denmark,
sweden} => {win} 0.006493506 0.8000000 1.1677725
14 {azerbaijan,
russia,
ukraine} => {win} 0.006493506 0.8000000 1.1677725
15 {norway,
russia,
ukraine} => {win} 0.006493506 0.8000000 1.1677725
16 {denmark,
russia,
ukraine} => {win} 0.006493506 0.8000000 1.1677725
17 {azerbaijan,
norway,
ukraine} => {win} 0.006493506 0.8000000 1.1677725
18 {azerbaijan,
denmark,
ukraine} => {win} 0.006493506 0.8000000 1.1677725
19 {denmark,
norway,
ukraine} => {win} 0.006493506 0.8000000 1.1677725
20 {azerbaijan,
norway,
russia} => {win} 0.006493506 0.8000000 1.1677725
21 {azerbaijan,
denmark,
russia} => {win} 0.006493506 0.8000000 1.1677725
22 {denmark,
norway,
russia} => {win} 0.006493506 0.8000000 1.1677725
23 {azerbaijan,
denmark,
norway} => {win} 0.006493506 0.8000000 1.1677725
24 {azerbaijan,
norway,
russia,
ukraine} => {win} 0.006493506 0.8000000 1.1677725
25 {azerbaijan,
denmark,
russia,
ukraine} => {win} 0.006493506 0.8000000 1.1677725
26 {denmark,
norway,
russia,
ukraine} => {win} 0.006493506 0.8000000 1.1677725
27 {azerbaijan,
denmark,
norway,
ukraine} => {win} 0.006493506 0.8000000 1.1677725
28 {azerbaijan,
denmark,
norway,
russia} => {win} 0.006493506 0.8000000 1.1677725
29 {azerbaijan,
denmark,
norway,
russia,
ukraine} => {win} 0.006493506 0.8000000 1.1677725
30 {azerbaijan,
georgia} => {win} 0.004870130 1.0000000 1.4597156
31 {georgia,
norway} => {win} 0.004870130 1.0000000 1.4597156
32 {favourites,
norway} => {win} 0.004870130 1.0000000 1.4597156





 The comparison of two models based on tweets mining, using syntactic parsing:
The comparison of two models based on tweets mining, using syntactic parsing: